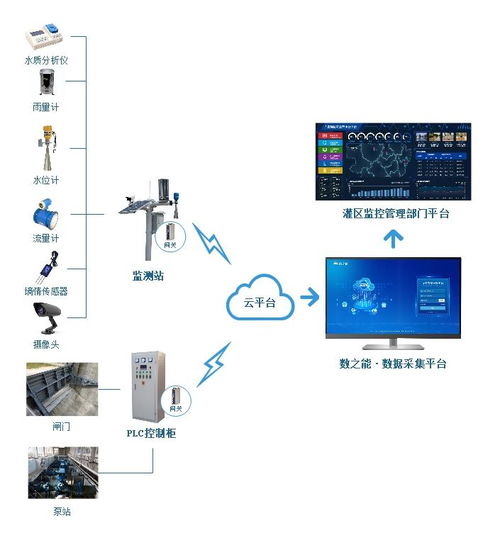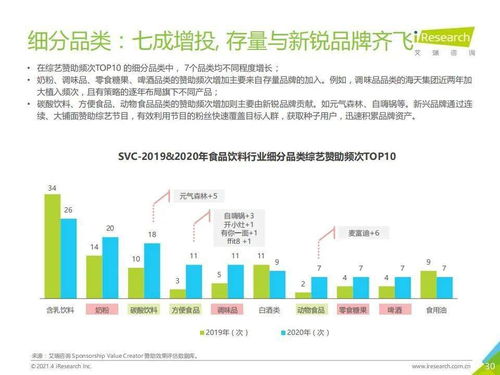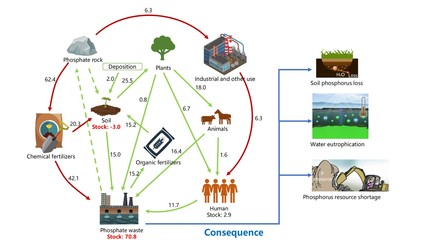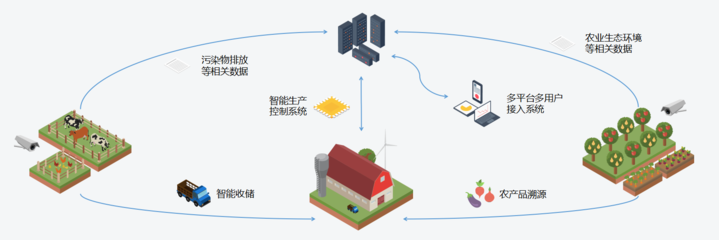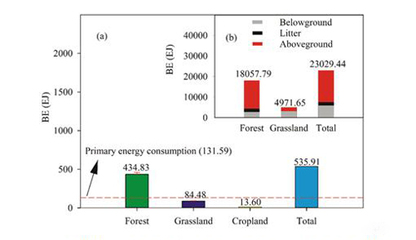
在推薦系統與深度學習融合的浪潮中,模型設計不斷向更精細、更復雜的結構演進。本文探討了一種名為“Non模型”的創新架構,它特別強調對域內信息的深度挖掘,并通過多模塊的非線性融合機制,實現了推薦性能的顯著提升。本文將結合其在生物質能資源數據庫信息系統這一特定垂直領域的應用場景,闡述該模型如何解決資源精準匹配與個性化推薦的難題。
一、Non模型的核心設計理念
Non模型并非指“無”模型,而是取其“非線性”(Non-linear)與“新穎”(Novel)之意。其核心設計理念圍繞兩點展開:
- 深度利用域內信息(In-Domain Information):傳統的推薦模型往往依賴通用的用戶-物品交互數據,但在生物質能等專業領域,數據具有強烈的領域特異性。例如,生物質資源的種類(如秸稈、林木剩余物)、熱值、含水率、收集半徑、轉化技術兼容性等,構成了豐富的域內屬性。Non模型通過設計專門的嵌入層和特征交叉網絡,將這些結構化與半結構化的域內信息深度編碼,作為推薦的重要依據,而不僅僅是輔助特征。
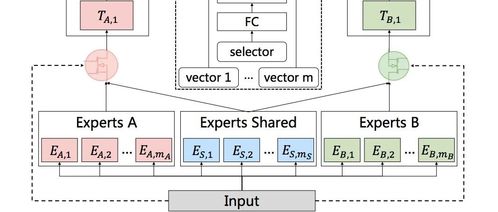
- 多模塊非線性融合(Multi-Module Non-linear Fusion):模型摒棄了簡單的拼接或加權平均的融合方式。它通常包含多個功能模塊:
- 域內特征深度提取模塊:利用注意力機制、圖神經網絡(GNN)等技術,挖掘資源屬性間、用戶需求與資源特性間的復雜關系。
- 用戶行為序列建模模塊:使用Transformer或GRU等捕捉用戶在數據庫系統中的歷史查詢、瀏覽、下載序列中的動態興趣。
* 上下文環境感知模塊:考慮時間(如季節對生物質資源可獲得性的影響)、地域、政策等上下文因素。
這些模塊的輸出并非直接匯聚,而是通過一個精心設計的非線性融合塔(如多層感知機MLP、基于門的融合網絡)進行高階交互和篩選,動態決定各模塊信息對最終推薦決策的貢獻度,從而實現“1+1>2”的融合效果。
二、在生物質能資源數據庫信息系統中的應用價值
生物質能資源數據庫信息系統匯集了海量的資源數據、技術方案、企業信息和政策法規。其用戶包括農戶、收儲商、能源企業、科研人員等,需求差異巨大。Non模型在該系統中的應用,能夠帶來革命性的體驗升級:
- 精準資源匹配:當一位能源企業用戶尋找特定熱值范圍、特定季節可大量獲取的生物質燃料時,模型能深度理解其查詢意圖(域內信息),并結合企業過往的采購偏好(行為序列),從海量數據庫中精準篩選并排序推薦最符合要求的資源供應信息,極大提升檢索效率。
- 個性化知識服務:對于科研人員,系統可以推薦與其研究課題高度相關的技術文獻、專利或案例數據(域內信息+行為序列)。模型能理解“纖維素乙醇預處理技術”與“木質素高值化利用”之間的深層次關聯,進行跨領域的智能推薦。
- 動態供需對接:模型可以融合實時或近實時的資源更新數據(如某地區新上報的秸稈儲量)、市場價格波動(上下文信息),動態為收儲商推薦潛在的高收益采購區域,或為資源持有者推薦最合適的潛在買家,促進產業鏈高效對接。
- 輔助決策支持:通過分析群體用戶的檢索和關注趨勢,模型可以幫助平臺運營者或政策制定者洞察區域生物質資源利用的熱點、難點和技術缺口,為產業規劃提供數據驅動的決策支持。
三、挑戰與展望
盡管Non模型展現出強大潛力,但在生物質能領域的應用仍面臨挑戰:域內專業知識的有效表示、小樣本冷啟動問題(如新上線的資源或新注冊的用戶)、數據質量與標準化程度不一等。未來的發展方向可能包括:
- 引入領域知識圖譜,更結構化地表征生物質能領域的復雜關系。
- 結合聯邦學習,在保護各參與方數據隱私的前提下,實現跨區域、跨平臺的聯合推薦。
- 開發可解釋性組件,讓推薦結果不僅準確,還能給出“為何推薦此資源”的合理解釋,增強用戶信任。
結論
Non模型通過聚焦域內信息和創新性多模塊融合,為推薦系統在生物質能這類垂直專業領域的深化應用提供了有力的技術框架。將其整合進生物質能資源數據庫信息系統,不僅能實現從“信息檢索”到“智能推薦”的跨越,更能激活數據價值,賦能生物質能產業鏈的各個環節,推動行業向數據化、智能化、高效化方向發展。這正體現了深度學習與垂直行業應用場景深度融合所產生的巨大能量。